aa_df['year'] = pd.to_datetime(aa_df['year'], format="%Y")#aa_df.set_index('year').reindex(pd.date_range('1900-01-01', '1930-12-31', freq='Y'))# Sort years and return unique years to check for missing dataaa_df['year'].sort_values().unique()
year gender (if known)
1900-01-01 male 5
female 1
1901-01-01 male 31
female 3
1902-01-01 male 5
female 1
1903-01-01 male 15
female 6
1904-01-01 male 12
1905-01-01 male 44
female 24
1906-01-01 male 55
female 22
1907-01-01 male 37
female 8
1908-01-01 male 10
female 1
1909-01-01 male 14
female 2
1910-01-01 male 4
female 1
1911-01-01 male 5
1912-01-01 male 3
female 2
1913-01-01 male 7
1914-01-01 male 6
female 1
1915-01-01 male 8
female 3
1916-01-01 female 11
male 8
1917-01-01 female 11
male 11
1918-01-01 male 8
female 4
1919-01-01 male 14
female 7
1920-01-01 male 8
female 7
1921-01-01 male 30
female 6
1922-01-01 female 8
male 5
1923-01-01 male 22
female 8
1924-01-01 female 32
male 26
1925-01-01 male 57
female 27
1926-01-01 male 47
female 30
1927-01-01 male 94
female 58
1928-01-01 male 66
female 33
Name: count, dtype: int64
# If there were missing years, this is how you might handle it# Create a dataframe with a complete range of years from 1900 to 1930# years = pd.DataFrame({'year': pd.date_range(start='1900', end='1930', freq='YS')})# Merge with existing dataframe# aa_gender_by_year = pd.merge(years, aa_gender_by_year, on='year', how='left')# Fill NaN values#aa_gender_by_year['gender (if known)'] = aa_gender_by_year['gender (if known)'].fillna("no author recorded")#aa_gender_by_year['count'] = aa_gender_by_year['count'].fillna(0)# Sort years and return unique years to check for missing data#aa_gender_by_year['year'].sort_values().unique()#aa_gender_by_year
Visualize with seaborn
Code
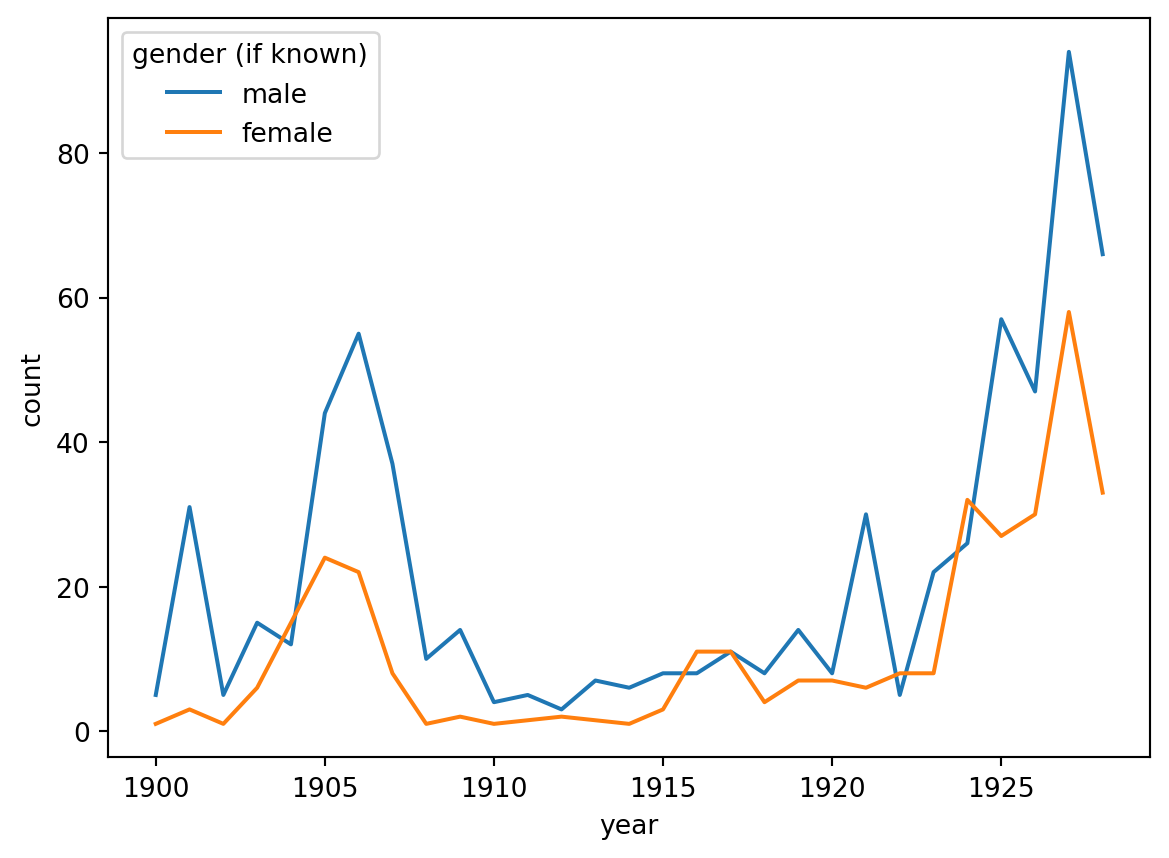
import seaborn as snsimport matplotlib.pyplot as pltimport matplotlib.dates as mdates# Create the line plotax = sns.lineplot(data=aa_gender_by_year, x="year", y="count", hue="gender (if known)")# Set x-axis major ticks to every 5 yearsax.xaxis.set_major_locator(mdates.YearLocator(5))# Format the x-axis labels to show the year only#ax.xaxis.set_major_formatter(mdates.DateFormatter('%Y'))
Code
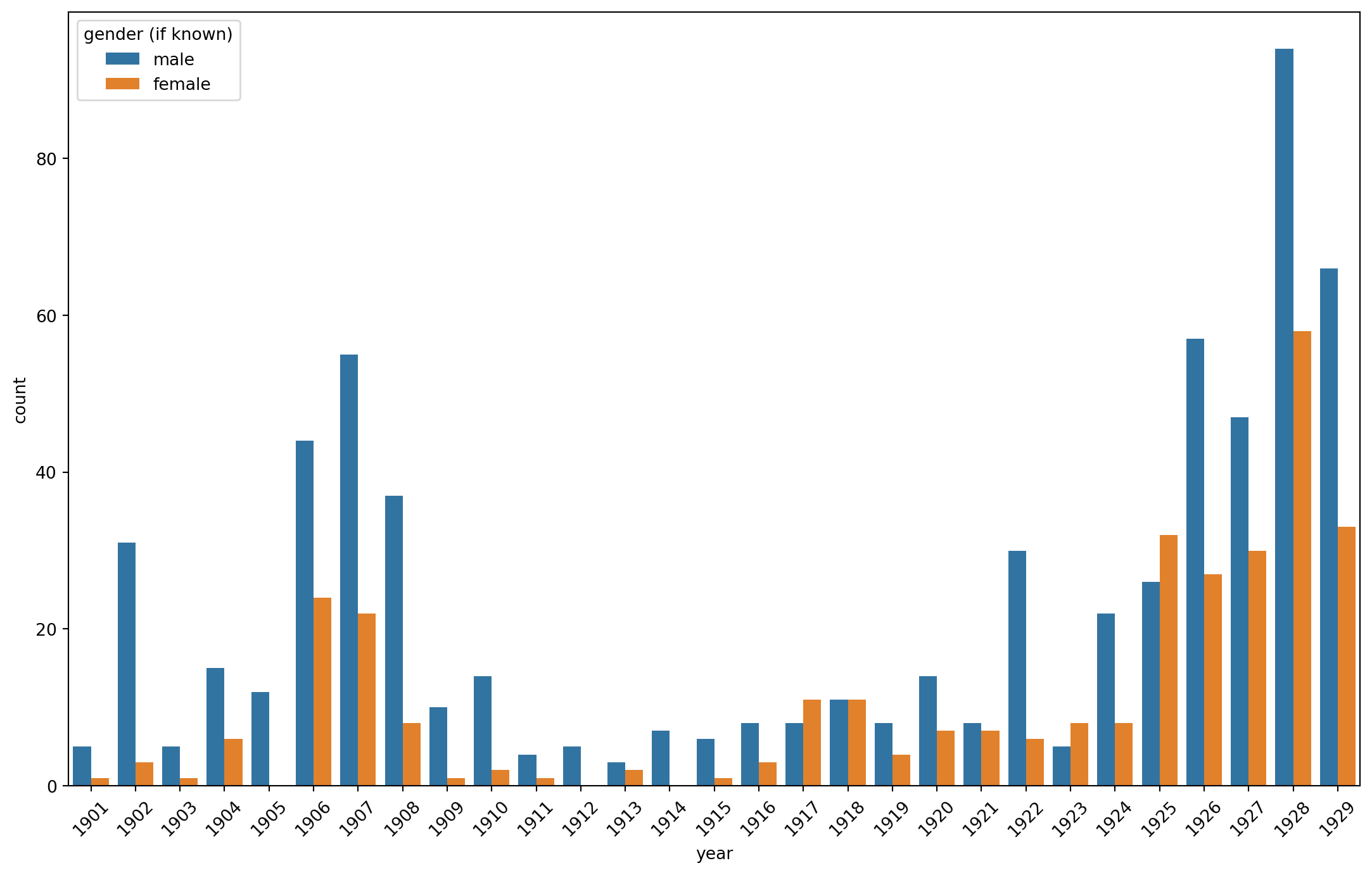
from matplotlib.ticker import MultipleLocatorplt.figure(figsize=(13.7, 8.27))# Create the bar plotax = sns.barplot(data=aa_gender_by_year, # pull out just the yearx=aa_gender_by_year["year"].dt.year, y="count", hue="gender (if known)")# Set x-axis major ticks every 1 yearax.xaxis.set_major_locator(MultipleLocator(1))# Set x-axis labels to the desired format (only show every 5th year)ax.set_xticklabels([date.year for date in pd.date_range(start='1900', end='1930', freq='YS')], rotation=45)plt.show()
/tmp/ipykernel_6267/3665439903.py:14: UserWarning:
set_ticklabels() should only be used with a fixed number of ticks, i.e. after set_ticks() or using a FixedLocator.
Make interactive visualizations with plotly
Code
import plotly.express as px# Create the interactive line plot with Plotlyfig = px.line(aa_gender_by_year, x='year', y='count', color='gender (if known)', title='Author Gender by Year')fig.show()
---title: "Visualize Author Gender By Year (Solution)"date: "2024-02-26"categories: [seaborn, plotly, interactive, line-plot, bar-plot, groupby, python, solution, exercise]toc: trueformat: html: default ipynb: defaultcode-overflow: wrapcode-fold: showeditor: visualdf-print: kableR.options: warn: falsecode-tools: trueexecute: eval: true---# Import pandas```{python}import pandas as pd```# Read in CSV```{python}aa_df = pd.read_csv("https://raw.githubusercontent.com/melaniewalsh/responsible-datasets-in-context/main/datasets/aa-periodical-poetry/African-American-Periodical-Poetry_1900-1928-Created-by-Amardeep-Singh-and-Kate-Hennessey,-Lehigh-University.csv")```# View first 5 rows```{python}aa_df.head()aa_df['gender (if known)'].value_counts()```# Convert year to datetime value```{python}aa_df['year'] = pd.to_datetime(aa_df['year'], format="%Y")#aa_df.set_index('year').reindex(pd.date_range('1900-01-01', '1930-12-31', freq='Y'))# Sort years and return unique years to check for missing dataaa_df['year'].sort_values().unique()```# Group by year, count instances of author by gender```{python}aa_df.groupby('year')['gender (if known)'].value_counts()```# Make this grouping into a dataframe```{python}aa_gender_by_year = aa_df.groupby('year')['gender (if known)'].value_counts().reset_index()#aa_gender_by_year['year'] = aa_gender_by_year['year'].astype(int)aa_gender_by_year``````{python}# If there were missing years, this is how you might handle it# Create a dataframe with a complete range of years from 1900 to 1930# years = pd.DataFrame({'year': pd.date_range(start='1900', end='1930', freq='YS')})# Merge with existing dataframe# aa_gender_by_year = pd.merge(years, aa_gender_by_year, on='year', how='left')# Fill NaN values#aa_gender_by_year['gender (if known)'] = aa_gender_by_year['gender (if known)'].fillna("no author recorded")#aa_gender_by_year['count'] = aa_gender_by_year['count'].fillna(0)# Sort years and return unique years to check for missing data#aa_gender_by_year['year'].sort_values().unique()#aa_gender_by_year```# Visualize with seaborn```{python}import seaborn as snsimport matplotlib.pyplot as pltimport matplotlib.dates as mdates# Create the line plotax = sns.lineplot(data=aa_gender_by_year, x="year", y="count", hue="gender (if known)")# Set x-axis major ticks to every 5 yearsax.xaxis.set_major_locator(mdates.YearLocator(5))# Format the x-axis labels to show the year only#ax.xaxis.set_major_formatter(mdates.DateFormatter('%Y'))``````{python}from matplotlib.ticker import MultipleLocatorplt.figure(figsize=(13.7, 8.27))# Create the bar plotax = sns.barplot(data=aa_gender_by_year, # pull out just the yearx=aa_gender_by_year["year"].dt.year, y="count", hue="gender (if known)")# Set x-axis major ticks every 1 yearax.xaxis.set_major_locator(MultipleLocator(1))# Set x-axis labels to the desired format (only show every 5th year)ax.set_xticklabels([date.year for date in pd.date_range(start='1900', end='1930', freq='YS')], rotation=45)plt.show()```# Make interactive visualizations with plotly``` {python}import plotly.express as px# Create the interactive line plot with Plotlyfig = px.line(aa_gender_by_year, x='year', y='count', color='gender (if known)', title='Author Gender by Year')fig.show()`````` {python}fig = px.bar(aa_gender_by_year, x='year', y='count', color='gender (if known)', title='Author Gender by Year')fig.show()```